实现order by的几种方式 #
使用索引 #
这是大多数情况下的最优解。索引中的数据是按照key的顺序进行排序的,所以可以直接使用索引进行排序。
使用临时表 #
本章不讨论这种方式。
使用文件排序 #
文件排序不一定是使用文件,也可能是使用内存。这种方式是在没有索引的情况下,MySQL使用的一种排序方式。
mysql关于order by的一个优化 #
如果排序没有用到索引,而是使用了文件排序,而且有条件limit row_count,那么MySQL会在找到row_count行之后,就不再进行排序了。这带来的一个问题是, 如果多条记录的排序列的值相同,那么MySQL不保证返回的记录的顺序。
下面举个例子: 示例表表结构如下:
CREATE TABLE `t10` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`c` int NOT NULL DEFAULT '0',
`d` int unsigned NOT NULL DEFAULT '0',
`f` int unsigned NOT NULL DEFAULT '0',
`e` int unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_cdf` (`c`,`d`,`f`),
KEY `idx_d` (`d`)
) ENGINE=InnoDB AUTO_INCREMENT=2249057 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
示例查询:
select * from t10 where c=5 order by e desc limit 0,3;
执行结果:
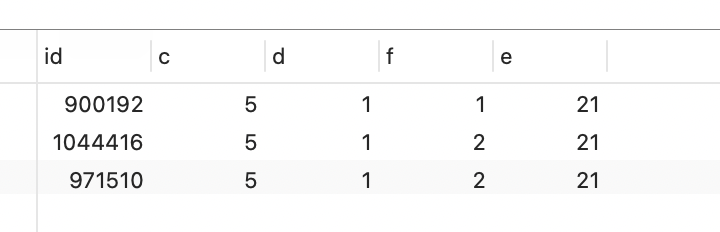
我们再多查询一条记录:
select * from t10 where c=5 order by e desc limit 0,4;
执行结果:

可以看到,前三条的顺序是不一样的。
解决办法 #
在order by条件中加上一个唯一的列,比如主键列,这样就可以保证返回的记录的顺序是一样的了。 例如:
select * from t10 where c=5 order by e desc,id desc limit 0,3;
在数据量大的时候,filesort的代价很高,会带来cpu使用率、磁盘io飙升的问题,影响其它正常业务。所以,尽量避免使用filesort。
MySQL8.0.21中的一个小优化 #
在MySQL8.0.21以前,如果查询有order by或group by,且有limit因子,那么优化器会尝试使用索引排序,这是默认且不能禁用的。 在MySQL8.0.21及以后的版本中,可以通过将prefer_ordering_index参数设置为false来禁用这个优化。这样做的原因是在部分场景下,选择使用排序索引的代价 可能更高。